Lesson 1.B.3 - Bias & Nonrandom Sampling

Key Question: Can data about colleges be misleading?
Content: Sampling Bias (Undercoverage, Nonresponse, Voluntary Response) | Response Bias (Question Wording, Self-Reporting)
Alignment: CED Topic 1.12
Video
Course Resources
Resources for teaching our AP® Statistics curriculum.
- Lesson Flow - timing and flow of class, using our lesson materials
- Pacing Guide - pacing our units, with daily or block schedules
- CED Alignment Guide - aligning our lessons to the AP® Statistics Course and Exam Description
Teaching Resources
Resources for teaching with Skew The Script.
- Discussion Norms - our model discussion norms for the classroom
- Letter to Parents - letter to share with parents about our nonpartisan approach
- Teaching Math on Civic Topics - tips for teaching math lessons that cover civic topics
Lesson Notes
Lesson-specific insights from the creators of this lesson.

High schoolers are inundated with university recruitment emails and mailers, which often contain seemingly impressive data about the colleges they promote. How are they supposed to separate the wheat from the chaff? In this lesson, students do a deep dive into the types of sampling bias that some colleges utilize in their promotional materials. After the lesson, students walk away with the ability to ask one of the most important questions for any data literate citizen: “That’s nice, but what was your sample?”
- Identify and describe the impacts of sampling bias (undercoverage, nonresponse, voluntary response)
- Identify and describe the impacts of response bias (question wording, self-reporting)
Before proceeding: Familiarize yourself with the lesson materials linked above (e.g. handout, handout key, slides, video). Then, for additional background and teaching tips from the lesson creators, check out the sections below.
- Consider asking students to bring in examples of college promotional emails or mailers they’ve received that contain data, or grab some from your school’s counselor(s). Using these artifacts to anchor the lesson can help emphasize the relevance of the lesson and of the skills that students learn.
- It’s important to emphasize that Palo Alto College is a community college. One key function of community colleges is to be a stepping stone towards transferring to a four-year college. So, both outcomes described in the lesson – obtaining full-time work and proceeding to the next level of schooling – are generally considered positive outcomes.
- On free response questions, if a student cannot recall which type of bias most applies to a situation (e.g. undercoverage vs nonresponse bias), it’s better for the student to generally describe the direction of a bias and how it arises, without trying to name the bias. Using the wrong name could lose points. That said, students taking the AP Exam may be asked to differentiate between the specific types of bias, especially on multiple choice questions. So, learning each of the bias names and the distinctions between them is still worthwhile.
First, download this lesson's Handout Key and read through its Discussion Question section. Then, check out our model discussion norms and the additional background notes below.
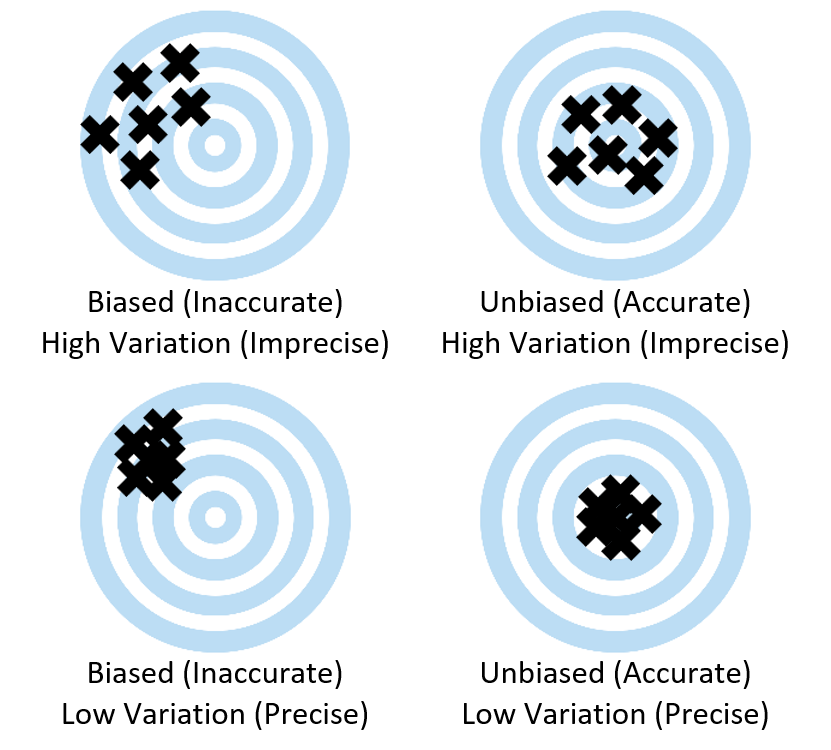
- The relative importance of unbiased estimates vs. precise estimates is a theme that will emerge throughout the course, especially as we dive into statistical inference. So, spending time here on why unbiasedness is more valuable than precision will help prime students for later conversations in the course.
- A helpful visual connection is the image of the targets from the handout in the prior lesson (Lesson 1.B.2). In particular, point students back to the targets in the bottom left corner and upper right corner. Which is better? This comparison makes it clear that it’s better to be “imprecisely right” (unbiased, imprecise) than “precisely wrong” (biased, precise). Hence, a smaller random sample is preferred to a larger nonrandom sample.
- This lesson’s key question (Can data about colleges be misleading?) is a repeat of the key question from the first lesson in our course sequence. We’re returning to this same topic to cover it more in-depth. The Palo Alto College example is the only example that is revisited, and we give it new vocabulary (undercoverage bias) and framing. All the other examples are new and deepen the analysis, so the lesson won’t feel redundant to students. In addition, students do not necessarily need to experience the first lesson in order to fully engage in this lesson. All the necessary background information is contained within this lesson.
- Graduation rate data can be found for almost every U.S. college through the IPEDS website. If there’s a college near your community that shares job placement rates only among graduates, you can use the IPEDS website to look up its graduation rate. If the graduation rate is low, consider replacing the Palo Alto College example with the more local college, to add extra relevance for students.
- The umbrella term “sampling bias” is not included in the AP Statistics CED. However, it is a helpful term to introduce pedagogically, so as to distinguish between the “sampling biases” that arise from flawed samples (undercoverage, nonresponse, volunteer response) and the “response biases” that arise from flawed measurements (question wording, self-reporting).
- Even with a random sample, estimates can still suffer from sampling bias. For example, imagine Palo Alto College obtained a random sample of graduates to estimate its job placement rate. Because this random sample was obtained only among the graduates, it will still suffer from undercoverage bias. The bias arises from the universe of possible individuals to sample (all the graduates) not matching the full population of interest (all enrolled students, whether or not they graduated). In statistical terms, the sampling frame (the universe of possible individuals to sample) did not match the full population. Although the term “sampling frame” is outside the scope of AP Statistics, learning about sampling frames can be helpful for understanding undercoverage bias.
Student Supports
Lesson-specific resources to support all learners.
- It can be tricky to determine the possible direction of a bias. Guiding students through a small sample size example can be helpful. For instance, ask students to imagine that only 5 people graduated from Rogers State University. Among those, only 1 responded to the survey. That person had found full-time employment. So, the estimate for the job placement rate would be 100%. Is this likely an overestimate or underestimate of the true job placement rate? Why?
- Another support for determining the direction of a bias is to ask students about who is excluded from a sample. Are the people excluded more likely or less likely to have a job? So, for the remaining people in the sample, will they overrepresent or underrepresent the rate of job placement? Why?
- Vocabulary used in the context of the lesson may include words that are unfamiliar or have several meanings. In particular, the following mathematical terms may need clarification or a definition provided:
- Bias
- Sampling Bias
- Undercoverage bias
- Nonresponse bias
- Voluntary response bias
- Response bias
- Question wording bias
- Self-reporting bias
- In addition, the following contextual terms may need clarification or a definition provided:
- Recruit
- Interminable
- It can be helpful to distinguish the mathematical/statistical definition of “bias” from its more commonly used meanings. In statistics, bias refers to the tendency of a sampling method to systematically over or underestimate a parameter’s true value.