Lesson 5.1 - Describing Two Quantitative Variables

Key Question: Would raising attendance also raise test scores?
Content: Describing Scatterplots | Correlation Coefficient (r) | Correlation vs Causation
Alignment: CED Topics 5.1-5.2
Video
Course Resources
Resources for teaching our AP® Statistics curriculum.
- Lesson Flow - timing and flow of class, using our lesson materials
- Pacing Guide - pacing our units, with daily or block schedules
- CED Alignment Guide - aligning our lessons to the AP® Statistics Course and Exam Description
Teaching Resources
Resources for teaching with Skew The Script.
- Discussion Norms - our model discussion norms for the classroom
- Letter to Parents - letter to share with parents about our nonpartisan approach
- Teaching Math on Civic Topics - tips for teaching math lessons that cover civic topics
Lesson Notes
Lesson-specific insights from the creators of this lesson.

Low-income students tend to have lower math exam scores, on average. In addition, low-income areas tend to have more chronically absent students. So, is the key to closing the achievement gap to first close the attendance gap? In this lesson, students analyze data that shows a strong association between attendance and test scores. Then, they confront a surprising result: in many districts that improved attendance, test scores didn’t significantly change. How is this possible? Students investigate.
- Determine the explanatory and response variables in bivariate quantitative data
- Describe form, direction, strength, and unusual features in scatterplots
- Use the correlation coefficient (r) to describe the strength and direction of an association
- Distinguish correlation from causation
Before proceeding: Familiarize yourself with the lesson materials linked above (e.g. handout, handout key, slides, video). Then, for additional background and teaching tips from the lesson creators, check out the sections below.
- Throughout the lesson, it is helpful to emphasize how remarkably strong the association is between attendance and test scores. The strength of the association, combined with its positive direction, will naturally entice students into viewing the relationship as causal. Then the discussion question’s result – that raising attendance did not significantly improve test scores – becomes even more surprising. The surprise sticks with students and serves as an anchor moment for distinguishing correlation from causation throughout the unit.
- This lesson introduces the language and tools students will use to describe relationships between two quantitative variables. As students learn to identify form, direction, strength, and unusual features, it can be helpful to continually comment on these features in the scatterplots they analyze throughout the unit. This practice supports later work in the unit with correlation, regression equations, and the coefficient of determination (\( r^2 \)).
First, download this lesson's Handout Key and read through its Discussion Question section. Then, check out our model discussion norms and the additional background notes below.
- The diagram below may be helpful when discussing the statement from the handout key: “Students experiencing poverty might not only face attendance barriers. They might also experience hunger or have less study time (due to working a job or taking care of siblings). Because of these confounding factors, focusing solely on attendance may not provide students with all the resources they need to be successful.”
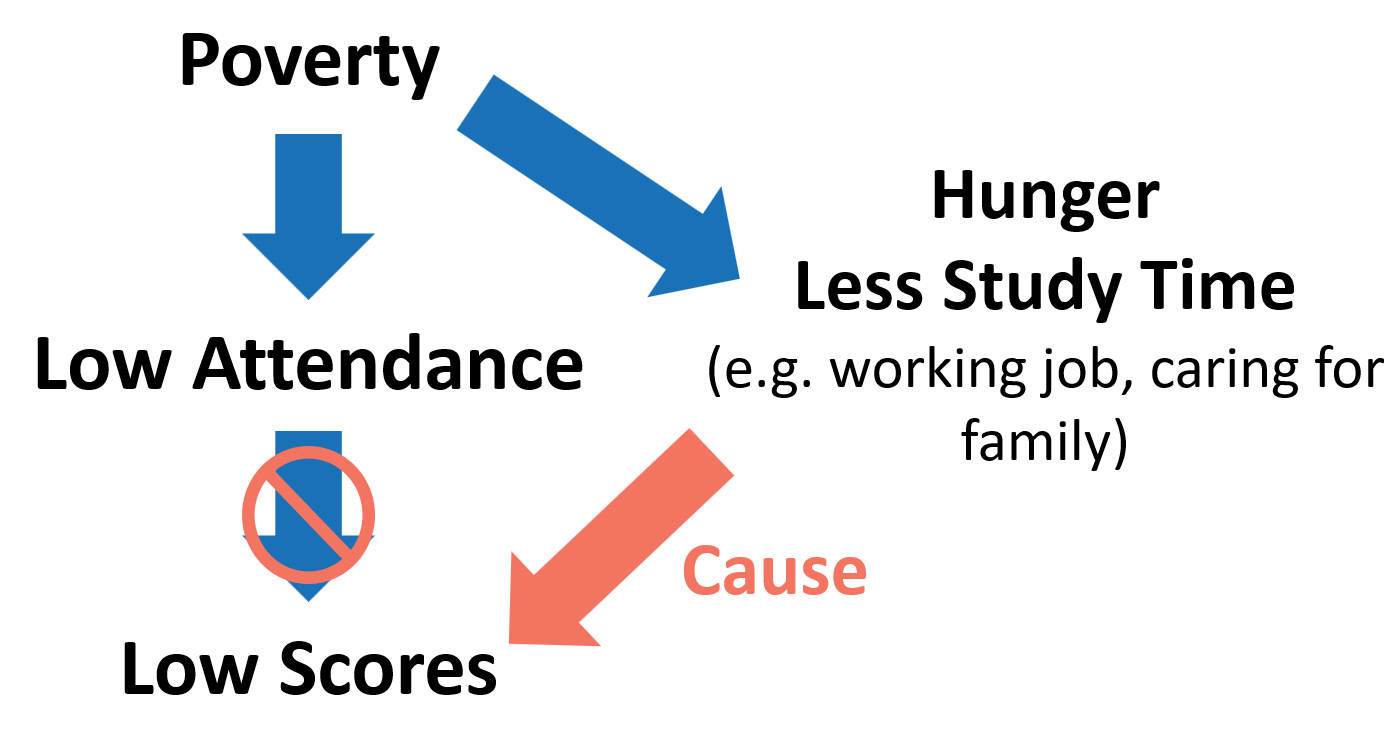
- There are additional possible confounding variables that students may identify during the discussion. Common examples include access to tutoring, housing stability, and school resources. The key idea is that these factors may simultaneously influence both attendance and academic achievement.
- This lesson also provides an opportunity to discuss why evidence of a strong association does not necessarily imply a causal relationship. Even when a relationship appears strong, alternative explanations should be considered before drawing causal conclusions.
- The attendance context provides a useful example of why strong associations should be interpreted cautiously. The lesson intentionally presents a remarkably strong positive relationship between attendance and achievement before introducing evidence that attendance interventions did not substantially improve test scores. This creates a natural opportunity to discuss the distinction between association and causation.
- Research on chronic absenteeism has found that attendance is associated with a wide range of student outcomes, particularly among students experiencing poverty. At the same time, researchers have identified many factors that influence attendance, including health, transportation, housing stability, family circumstances, and school conditions. These factors provide concrete examples of potential confounding variables that may influence both attendance and academic achievement.
- There are three common correlation / causation fallacies. The AP Statistics course primarily focuses on the first, but it is helpful to understand all three:
- Confounding variable fallacy: A lurking variable influences both the explanatory and response variables simultaneously, creating the observed association. This is the primary focus of the lesson’s attendance example.
- Directional fallacy: Occurs when we believe X causes Y, but in reality, Y causes X. For example, we might assume that higher attendance causes stronger academic performance, when in reality stronger academic performance increases engagement with school and leads to higher attendance rates.
- Spurious correlation fallacy: Two variables are correlated purely by chance, despite having no meaningful connection. For striking examples of these, check out the collection of spurious correlations from Tyler Vigen. Examples include the surprisingly strong correlations between: the divorce rate in Maine and per capita consumption of margarine; the number of letters in national spelling bee winning words and the number of people killed by venomous spiders; and the per capita consumption of chicken and total US crude oil imports.
- The terms explanatory variable and response variable are preferred over independent variable and dependent variable because they imply fewer assumptions about the nature of the relationship. In many observational studies, one variable may help explain or predict another, without implying a causal relationship. Using explanatory and response language helps reinforce this distinction early in the course, rather than using “dependent” (which could imply causation). In addition, the word independent already has a specific meaning elsewhere in statistics and probability, so this terminology helps avoid unnecessary ambiguity.
- A large-magnitude correlation coefficient does not guarantee that a linear model is appropriate. Anscombe’s Quartet provides a striking example: four data sets with identical correlation coefficients can exhibit dramatically different patterns, including non-linear relationships and influential outliers. Reinforce that scatterplots should always be examined before interpreting r.
- Outliers in a bivariate setting differ from outliers in a univariate setting. A point is not necessarily unusual simply because it is far from the other observations. Instead, an outlier is a point that does not follow the overall pattern seen in the data. This idea will be revisited later through residuals and regression.
Student Supports
Lesson-specific resources to support all learners.
- For confounding variables, it can be helpful to begin with a simpler example before discussing attendance and achievement. The classic ice cream sales and drowning example provides a straightforward introduction to the idea of a lurking variable before students encounter the more nuanced discussion of poverty, attendance, and achievement.
- Deciding when a linear model is appropriate can be challenging. Students sometimes focus on the fact that points do not lie perfectly on a line and conclude that a linear model is inappropriate. It can be helpful to encourage students to focus on the overall pattern of the data rather than individual deviations from the trend.
- Encourage students to examine the scatterplot before calculating the correlation coefficient. A large-magnitude r value does not guarantee that a linear model is appropriate, and a scatterplot is necessary to assess form, unusual features, and potential outliers before interpreting the correlation.
- Vocabulary used in the context of the lesson may include words that are unfamiliar or have several meanings. In particular, the following mathematical terms may need clarification or a definition provided:
- Bivariate
- Explanatory variable
- Response variable
- Scatterplot
- Association
- Correlation
- In addition, the following contextual terms may need clarification or a definition provided:
- Attendance
- Attendance case managers
- Ride shares
- Common synonyms for the explanatory variable include factor, independent variable, predictor, feature, or input. Common synonyms for the response variable include dependent variable, target, or output.
- It’s helpful to reinforce that the terms association and correlation are related, but they’re not quite synonyms. We use the term correlation to describe the linear relationship between two variables. We use the term association to describe any noticeable relationship between two variables – whether the form of that association is linear or non-linear.